[Python] Pandas 파이썬 판다스 라이브러리 포스팅 하나로 개념부터 정리하기
Pandas!
저번 Numpy에 이어서 이번 포스팅은 Pandas에 대한 개념과 기초 문법에 대해서 설명해보도록 하겠다.
판다스에 대해서는 데이터 분석 실습하면서 이런게 있구나~ 하는 정도만 알았는데
이번 기회에 포스팅 하면서 좀 더 자세히 알아보도록 하려고 한다.
Pandas
판다스(Pandas)란?
구조화된 데이터를 효과적으로 처리하고 저장할 수 있는 파이썬 라이브러리이다.
numpy를 기반으로 만들어져서 좀 더 다양한 기능들을 제공한다.
의외로? 엑셀도 데이터 분석 툴이다.
일반 사용자들이 보다 편하게 데이터들을 정리하고, 계산하고, 간단한 분석을 할 수 있도록 인터페이스를 만든 프로그램이다.
판다스는 엑셀을 코딩으로 한다고 생각하면 편할 것같다.
Series(시리즈)
numpy array가 보강된 형태 Data와 Index를 가지고 있다.
numpy의 array 와 Series비교를 위해서
Numpy를 이용해서 배열을 가져와보았다.
>>> import numpy as np
>>> np.array([1,2,3,4], dtype = 'int')
array([1, 2, 3, 4])
아래 코드는 판다스를 import해서 배열을 가져와봤다.
>>> import pandas as pd
>>> data = pd.Series([1,2,3,4])
>>> data
0 1
1 2
2 3
3 4
dtype: int64
별 다른 설명이 없이도,
출력값에서 확연한 차이가 보인다.
첫번째 열 0 1 2 3 은 Index를 나타내고
두번째 열 1 2 3 4 는 Data 즉, 우리가 시리즈로 만든 리스트의 요소가 나타난다.
가장 아래에는 dtype이 출력된다.
numpy array와 Series의 가장 큰 차이는 Index의 유무이다.
>>> data = pd.Series([1,2,3,4], index = ['a','b','c','d'])
a 1
b 2
c 3
d 4
dtype: int64
>>> data['c']
3
위 코드처럼 index를 지정해 줄 수도 있고,
index값으로 data를 찾을 수 있다.
여기서,
뭔가와 비슷하다는 생각이 든다.
바로.!
key값을 이용해서 Value를 찾는 딕셔너리와 비슷하다.
my_dict ={
'성' : '이',
'이름' : '은지',
'나이' : 24,
'직업' : '백수'
}
my_data = pd.Series(my_dict)
다음과 같이 딕셔너리를 이용해서도 Series를 만들 수 있다.
>>> my_data
성 이
이름 은지
나이 24
직업 백수
dtype: object
딕셔너리의 key => Index
딕셔너리의 value => data
가 된다.
DataFrame (데이터 프레임)
여러 개의 Series가 모여서 행과 열을 이룬 데이터이다.
color_dict = {
'apple' : 'red',
'banana' : 'yellow',
'grape' : 'pupple',
'tomato' : 'red'
}
cal_dict = {
'apple' : 10,
'banana' : 23,
'grape' : 15,
'tomato' : 30
}
color = pd.Series(color_dict)
cal = pd.Series(cal_dict)
fruits = pd.DataFrame({
'cal' : cal,
'color' : color
})
1. color_dict와 cal_dict로 Series를 만들어서 각각 color와 cal이라는 변수에 저장.
2. pd.DataFrame을 사용해서 데이터 프레임을 만듬.
결과:
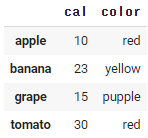
이렇게 이쁜(?) 표로 보기 좋게 정리가 되서 나온다.
딕셔너리의 key는 Index가 되었고,
cal 컬럼과 color컬럼의 data가 각각에 맞게 들어가있다.
>>> fruits.index
Index(['apple', 'banana', 'grape', 'tomato'], dtype='object')
>>> fruits.columns
Index(['cal', 'color'], dtype='object')
.index 는 Index값을 확인할 수 있고,
.columns 는 칼럼 값을 확인할 수 있다.
>>> fruits['cal']
apple 10
banana 23
grape 15
tomato 30
Name: cal, dtype: int64
>>> type(fruits['cal'])
pandas.core.series.Series
cal의 정보만 따로 뽑고싶다면,
fruits['cal']을 해주면된다.
데이터 타입도 type()을 이용하면 쉽게 알 수 있다.
#저장하기
fruits.to_csv("./fruits.csv")
fruits.to_excel("./fruits.excel")
#불러오기
fruits = pd.read_csv("./fruits.csv")
fruits = pd.read_csv("./fruits.excel")
정갈?하게 데이터가 잘 정돈되어 있기 때문에
위 코드로 csv나 excel로 저장과 불러오기가 가능하다.
Indexing & Slicing (인덱싱 & 슬라이싱) - loc / iloc
데이터의 값을 찾고 변경하는 인덱싱과 슬라이싱 문법을 알아보도록 하자.
loc
>>> fruits.loc['apple']
cal 10
color red
Name: apple, dtype: object
과일데이터에서 apple 데이터만 뽑아달라는 코드를 적어보았다.
Name이 apple로 바뀐 것을 확인할 수 있다.
fruits.loc['apple': 'grape', :'color']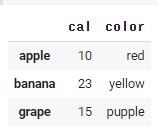
슬라이싱은 위 코드로 진행할 수 있다.
apple부터 grape까지, color까지 포함하는 데이터를 뽑는다는 뜻이다.
iloc
정수 인덱스로 인덱싱과 슬라이싱이 가능하다.
>>> fruits.iloc[0]
cal 10
color red
Name: apple, dtype: object
0번째 인덱스! 즉, apple의 정보를 보여준다.
fruits.iloc[1:3, :1]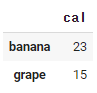
1부터 3이전까지의 인덱스, 1 이전까지의 컬럼 데이터를 보여줘라는 뜻으로
파이썬이나 넘파이에서 슬라이싱 했던 개념과 같다고 생각하면 된다.
새 데이터 추가, 수정
dataframe = pd.DataFrame(columns = ['이름','나이','주소'])
dataframe.loc[0] = ['이은지' , '26', '전주']
dataframe.loc[1] ={'이름' : '다롱', '나이' : '10', '주소': '서울'}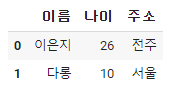
1. 데이터 프레임을 만든다. columns의 이름은 이름, 나이, 주소이다.
2. (리스트로 추가하는 방법) loc[0]은 0번째 인덱스에 data를 넣겠다는 뜻이 된다.
3. (딕셔너리로 추가하는 방법) loc[1]은 1번째 인덱스에 data를 넣겠다는 뜻이다. Key값은 columns가 되고 values값은 data가 된다.
다음과 같이 데이터를 수정하기도 한다.
dataframe.loc[1,'주소'] = '전주'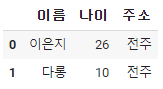
첫 번째 인덱스의 '주소' colums를 '전주'로 바꿔보았다.
새로운 colums를 추가해보자.
dataframe['전화번호'] = np.nan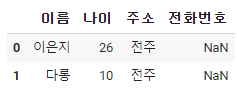
dataframe['원하는 colums이름'] = data
로 만들어 주면 된다.
* np.nan은 Not a number의 줄임말로 값이 없을 때 사용한다.
dataframe.loc[0,'전화번호'] = '010-1234-5678'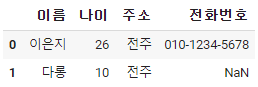
0번째 인덱스의 , 전화번호를 추가해주고, 이번에는 번호도 적어주었다.
컬럼을 선택하는 법을 알아보자.
>>> dataframe["이름"]
0 이은지
1 다롱
Name: 이름, dtype: object
dataframe 의 리스트안에 컬럼이 하나만 들어가 있으면 => Series가 된다.
위 코드를 보면 "이름" 컬럼의 data와 그에 대한 이름, dytpe 설명이 나와있다.
하지만
dataframe[["이름","주소","나이"]]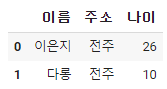
dataframe의 리스트 안에 컬럼이 두개 이상이 리스트로 들어가 있다면 => DataFrame이 된다.
코드는
이름, 주소, 나이 컬럼의 DataFrame을 출력한 것이다.
누락된 데이터 체크 isnull /notnull / dropna / fillna
데이터 분석에서는 누락데이터를 다루는 것은 중요하다.
누락 데이터를 처리하지 않고 분석을 하게 된다면 결과에 큰 영향을 끼칠 수 있다.
따라서.
누락된 데이터를 삭제하거나, 다른 대체값으로 채워주는 등의 정제가 필요하다
누락 데이터 확인법
dataframe.isnull()
dataframe.notnull()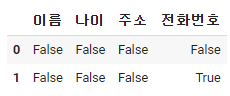

isnull()은 비어있는 데이터가 비어있는지 체크 => 비어있으면 Ture
notnull()은 비어있지 않은 경우에 대해서 체크 => 비어있지 않으면 Ture
dataframe.dropna()
dropna()를 활용하여
데이터 프레임의 결측지 행을 없애버린다.
dataframe['전화번호'] = dataframe['전화번호'].fillna('전화번호 없음')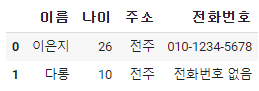
fillna()는 결측치 부분에 다른 값을 넣어주는 함수이다.
Series 연산
Series도 연산이 가능하다.
>>> A = pd.Series([2,4,6], index = [0,1,2])
0 2
1 4
2 6
dtype: int64
>>> B = pd.Series([1,3,5], index = [1,2,3])
1 1
2 3
3 5
dtype: int64
A는 인덱스가 0,1,2으로 지정했고,
B는 인덱스를 1,2,3으로 지정했다.
이 경우
A+B를 하면 어떻게 될까?
>>> A+B
0 NaN
1 5.0
2 9.0
3 NaN
dtype: float64
A는 인덱스 0이 있지만, B는 인덱스 0이 없기 때문에,
연산을 하면 NaN이 나온다.
A인덱스1(4) + B인덱스1(1) = 5.0
A인덱스2(6) + B인덱스2(3) = 9.0
A인덱스3(없음) + B인덱스3(5) = NaN
그리고 정수 타입처럼 계산을 했지만, 결과는 실수로 나오는 것도 확인할 수 있다.
그런데
만약 NaN을 만들고 싶지 않다면 어떻게 해야할까?
>>> A.add(B, fill_value = 0)
0 2.0
1 5.0
2 9.0
3 5.0
dtype: float64
이렇게 fill_value를 활용하여
인덱스가 없는 곳에 0을 채우기가 가능하다.
더하기로 예를 들었지만,
add(+) -> 더하기
sub(-) -> 빼기
mul(*) -> 곱하기
div(/) -> 나누기
연산이 당연히 가능할 뿐만 아니라
넘파이에서 사용했던
집계함수(sum(), mean())등도 활용할 수 있다.
값으로 정렬하기 - sort_values()
데이터 프레임을 만들어 보았다.
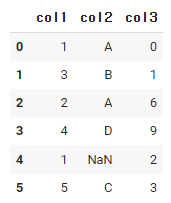
df = pd.DataFrame({
'col1' : [1,3,2,4,1,5],
'col2' : ['A','B','A','D',np.nan,'C'],
'col3' : [0,1,6,9,2,3]
})
df.sort_values('col1')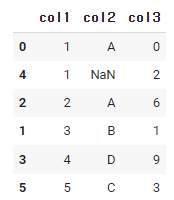
df.sort_values 안에 컬럼 값을 넣으면 그 컬럼의 data들이 정렬된다.
위 코드로 인해서
col1의 data들이 오름차순으로 정리 된 것을 볼 수 있다.
(만약 NaN이 있다면 가장 마지막)
df.sort_values('col1', ascending = False)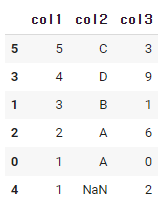
앞서 말했듯이 기본적으로 오름차순 정렬이지만,
ascending의 값을 False로 준다면 내림차순으로 정렬이 된다.
df.sort_values(['col2','col1' ])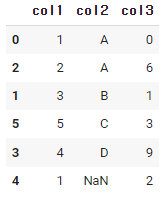
컬럼을 리스트로 두개를 넣는다면,
첫번째로 입력한 컬럼부터 정렬이 된 후, 두번째 컬럼이 정렬된다.
위 예를 보면,
col2가 먼저 정렬이 되었는데, A가 2개 있다.
col2의 A,A의 순서를 정하기 위해서 두번째 컬럼 col1의 정렬을 기준으로 인덱스가 정렬 된 것을 확인할 수 있다.
조건으로 검색
df = pd.DataFrame(np.random.rand(5,2), columns = ["A", "B"])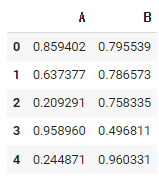
다음과 같은 데이터 프레임이 있다.
>>> df["A"] < 0.5
0 True
1 True
2 True
3 False
4 True
Name: A, dtype: bool
A컬럼에 데이터가 0.5보다 작다는 조건을 걸고 출력하면
Ture와 False로 출력이 된다.
조건을 두개 달아보자.
>>> (df["A"]<0.5) & (df["B"]>0.3)
0 False
1 False
2 True
3 False
4 True
dtype: bool
A 컬럼 data가 0.5보다 작고 B컬럼 데이터가 0.3보다 작다.
를 계산한 코드와 출력값이다.
bool이 아닌 숫자형으로도도 표현할 수 있다.
두 가지 방법이 있다
>>> df[(df["A"]<0.5) & (df["B"]>0.3)]
>>> df.query("A<0.5 and B>0.3")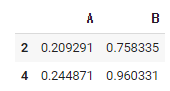
1. 앞선 코드 조건식에서 df를 리스트로 씌워준다.
2. df.query 라는 함수를 사용해서 조건을 넣어준다.
문자열을 검색하는 방법을 간단하게 알아보도록 하자.
1. df["칼럼"].str.contains("데이터")
2. df.칼럼.str.match("데이터")
3. df["칼럼"] == "데이터"
함수로 데이터 처리 - apply / replace
df = pd.DataFrame(np.arange(5), columns = ["Num"])
다음과 같은 데이터 프레임에 함수를 만들어서 적용시켜보자.
def square(x):
return x**2
square라는 함수는 x를 받으면 x의 두제곱이 되어서 리턴한다.
>>> df["Num"].apply(square)
0 0
1 1
2 4
3 9
4 16
Name: Num, dtype: int64
apply()에 함수 이름을 그대로 넣으면
시리즈 형태의 출력값이 나온다.
데이터프레임의 데이터 값에 2를 제곱한 결과를 볼 수 있다.
lambda를 사용하면 더 간단하게 코드를 줄일 수 있다.
df.Num.apply(lambda x:x**2)
lambda는 정말 많이 쓰이는 함수인데 일반 함수를 를 한 줄 형태로 간결하게 해준다.
<lambda 관련 포스팅보기>
↓↓↓↓↓↓
https://eunjibest.tistory.com/13?category=911295
[Python] lambda function - 파이썬 람다(Lambda)함수
python lambda function - 파이썬 람다(Lambda)함수 람다(Lambda)함수 lambd는 함수 를 생성할 때 사용하는 예약어로 def와 동일한 역할을 한다. 일반 함수를 한줄로 간결하게 만들 때 사용된다. def를 사용.
eunjibest.tistory.com
잠시 위에서 했던 furits 예제로 돌아가보자,
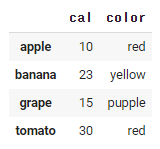
>>> fruits.cal.replace({10 : 15, 15 : 10})
apple 15
banana 23
grape 10
tomato 30
Name: cal, dtype: int64
replace()를 이용하여, 데이터 값만 대체가 가능하다.
데이터프레임.칼럼.replace({현재 데이터 : 바꿀 데이터})
fruits의 cal 칼럼의 10 데이터가 15로 바뀌고, 15데이터, 10으로 바뀌었다.
현재 출력값이 시리즈 형태로 나와있는데,
데이터 프레임 형태로 바꾸기 위해서는 아래와 같은 코드를 입력하면 된다,.
fruits.cal.replace({10 : 15, 15 : 10}, inplace = True)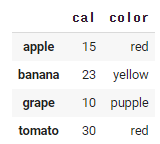
inplace = Ture를 뒤에 붙여주면
데이터 프레임 형태로 출력이된다.
그룹 - groupby / agrregate / filter / apply / get_group
다음과 같은 데이터 프레임이 있다.
df = pd.DataFrame({'key' : ['A','B','C','A','B','C'],
'data1' : [1,2,3,1,2,3],
'data2' : np.random.randint(0,6,6)})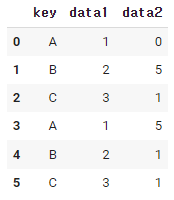
df.groupby('key').sum()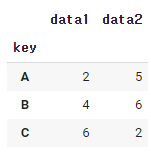
groupby()는 해당 칼럼 기준으로 합계를 구하라는 뜻이다.
위 예제를 살펴보면
1. df.groupby('key')를 하면 key의 데이터가 같은 것끼리 묶인다. (A,A) /(B,B)/(C,C)
2. A인덱스의 data1의 데이터는 1,1이다. 1+1 =2
3. B인덱스의 data1의 데이터는 2,2이다. 2+2 = 4
4. C인덱스의 data1의 데이터는 3,3이다. 3+3 = 6
마찬가지로 data2에도 똑같이 적용하면
0+5 = 5, 5+1 = 6, 1+1 =2 가 된다.
aggregate에 대해서 알아보자.
다음과 같은 임의의 데이터 프레임이 있다.
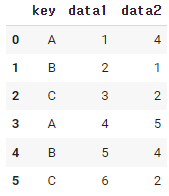
df.groupby('key').aggregate(['min', np.median, max])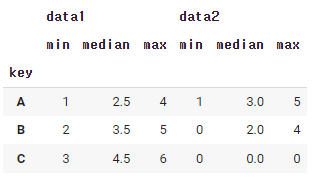
칼럼 key를 기준으로 groupby를 해주고,
aggregate를 사용해서, 최소, 중간, 최대값을 뽑아보았다.
칼럼 key의 데이타 A기준 data1 : (1,4)중 가장 작은 값은1, 중간값은 2.5, 가장 큰 값은 4이다.
칼럼 key의 데이타 B기준 data1 : (2,5)중 가장 작은 값은2, 중간값은 3.5, 가장 큰 값은 5이다.
칼럼 key의 데이타 C기준 data1 : (3,6)중 가장 작은 값은3, 중간값은 4.5, 가장 큰 값은 6이다.
data2에도 똑같은 적용을 하면, 위와 같은 데이터 프레임이 만들어진다.
칼럼은 data1과 data2가 되고 그 밑에 멀티 인덱스라고 부르는(min, median, max)를 볼 수 있다.
df.groupby('key').aggregate({'data1':'min','data2':np.sum})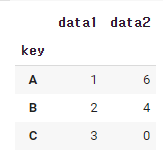
이렇게 딕셔너리 형태를 이용해서, 각각의 컬럼별로 따로따로 집게가 가능하다.
data1은 최소값을 구하고, data2는 합을 구하라는 뜻이다.
filter()는 groupby를 통해서 그룹 속성을 기준으로 데이터를 필터링 하는 함수이다.
다음과 같은 데이터 프레임이 있다.
def filter_by_mean(x):
return x['data2'].mean() > 2
df.groupby('key').filter(filter_by_mean)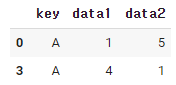
data2의 평균이 2보다 큰 값을 반환시키는 함수를 만들어주고
filter에 함수를 넣으면, 평균값이2보다 큰 데이터들이 추출된다.
groupby에서도 apply함수가 적용이 가능하다.
df.groupby('key').apply(lambda x: x.max() - x.min())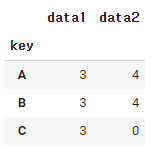
groupby된 key에다가 최대값-최소값을 반환시켜주는 함수를 apply에 넣어 연산한다.
get_group은 groupby로 묶인 데이터에서 key값으로 데이터를 가져올 수 있다.
df.groupby('key').get_group('A')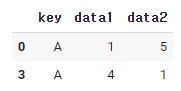
컬럼 key로 묶인 데이터중에서 'A'데이터를 가져오라는 뜻이다.
MultiIndex(멀티 인덱스)
멀티인덱스는 인덱스를 계층적으로 만들 수 있다.
위에서 aggregate()를 사용할 때 출력값으로 멀티 인덱스가 나온 것을 볼 수 있었다.
조금 자세히 설명해보도록 하겠다.
df = pd.DataFrame(
np.random.randn(4,2),
index = [['A','A','B','B'], [1,2,1,2]],
columns = ['data1', 'data2']
)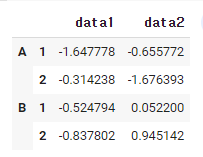
데이터 프레임을 만들어보았다.
지금까지 만들었던 것과 조금 다른 것이 보인다.
바로 인덱스 리스트가 [[ ]] 이렇게 두번 쌓여져 있는 것을 볼 수 있다.
첫 번째 리스트가 인덱스 순서가 더 높다.
위 예제에서는 A가 2개 B가 2개이므로 중복되는 요소들이 하나로 묶인 것을 확인할 수 있다.
두 번째 리스트 역시 순서대로 1,2,1,2 로 들어가있는 것을 볼 수 있다.
마찬가지로
열 인덱스도 계층적으로 만들 수 있다.
df = pd.DataFrame(
np.random.randn(4,4),
columns = [['A','A','B','B'], [1,2,1,2]],)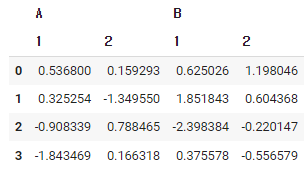
첫 번째 오는 리스트가 컬럼(A,A,B,B)이 되고
두 번째 오는 리스트가 각각의 컬럼 안에 열 인덱스가 된다.
참고로 멀티인덱싱에서도 loc과 iloc을 사용하여 인덱스 탐색이 가능하다.
pivot_table
피봇 테이블! 엑셀에서 많이 보던 용어이다.
똑같다. 데이터에서 필요한 것들만 뽑아서 새롭게 요약하고 분석을 할 수 있다.
가계부를 예로 든다면,
이번달 지출액 중에서 택시 비용의 평균은 얼마인지?
이번달 배달음식 소비가 저번달보다 얼마나 줄었는지 등...
따라서 실습을 보여주기에는
꽤 많은 양의 데이터들이 필요하기 때문에
간단한 설명만 해주겠다ㅠ
df.pivot_table(
index = '행 인덱스로 들어갈 key', columns = '열 인덱스로 라벨링이 될 값', values = '분석할 데이터',
aggfunc = 분석할 데이터의 계산 방법
)
index = 행 인덱스로 들어갈 key
columns = 열 인덱스로 라벨링이 될 값
values = 분석할 데이터
기본적으로 위 문법을 이용하여 분석할 수 있다.
자세한 사용법은 데이터 분석 포스팅을 하게 된다면 보여드릴 기회가 있을 것같다.
이렇게해서
데이터를 꽤나 편하게 다룰 수 있는 판다스 문법에 대해서 알아보았다!
이 역시 필수적인 문법들만 정리를 해둔 것이기 때문에
또 다른 문법들을 소개할 기회가 있으면 포스팅을 할 예정이다.

개발자가 아닌 마케터나, 기획자등 다른 분야 종사자 분들도
엑셀 및 데이터 정리를 빠르고, 효율적으로 이용하기 위해서
많이 배우는 추세라고한다!
우리 구독자 분들도 이 기회에 파이썬 한 번 맛들려보시는거 어떠신지요..ㅎ
'Programming > Python' 카테고리의 다른 글
| [Python] 파이썬 Set / 집합 자료형 / 집합연산 / 집합계산 알아보기! (3) | 2022.05.08 |
|---|---|
| [Python] Matplotlib 파이썬으로 데이터 시각화 하기. / line plot / Scatter plot / Bar plot / Histogram (10) | 2022.05.06 |
| [Python] Numpy 파이썬 넘파이 라이브러리 포스팅 하나로 개념부터 정리하기. (10) | 2022.05.02 |
| [BAEKJOON] 백준 Python 5단계 함수 15596번 / 4673번/ 1065번 / 정수 N개의 합 / 셀프 넘버 / 한수 (6) | 2022.04.27 |
| [BAEKJOON] 백준 Python 4단계 1차원 배열 8958번/ 4344번 / OX퀴즈 / 평균은 넘겠지 (8) | 2022.04.17 |




댓글