[딥러닝] Embeding Layer / 차원의 저주 (curse of dimensionality) /자연어 처리 / 단어 백터화
차원의 저주 (curse of dimensionality)
I am a boy and I am not a girl
위 문장의 각각의 단어들에 고유의 숫자를 줘보았다.
I -> 0
am -> 1
a -> 2
boy -> 3
and -> 4
not -> 5
girl ->6

이 숫자들을 one-hot encording을 해줘야한다.
왜냐하면 각각의 숫자에 연관성을 없애주기 위해서이다.
예를 들면 am + a = boy
이런식으로 관계가 지어져서 이상한 해석을 할 수 있기 때문이다.
one-hot encording을 해주면
I -> [1, 0, 0, 0, 0, 0, 0 ]
am -> [0, 1, 0, 0, 0, 0, 0 ]
a -> [0, 0, 1, 0, 0, 0, 0 ]
boy -> [0, 0, 0, 1, 0, 0, 0 ]
and -> [0, 0, 0, 0, 1, 0, 0 ]
I -> [1, 0, 0, 0, 0, 0, 0 ]
not -> [0, 0, 0, 0, 0, 1, 0 ]
a -> [0, 0, 1, 0, 0, 0, 0 ]
girl ->[0, 0, 0, 0, 0, 0, 1 ]
이렇게 된다.
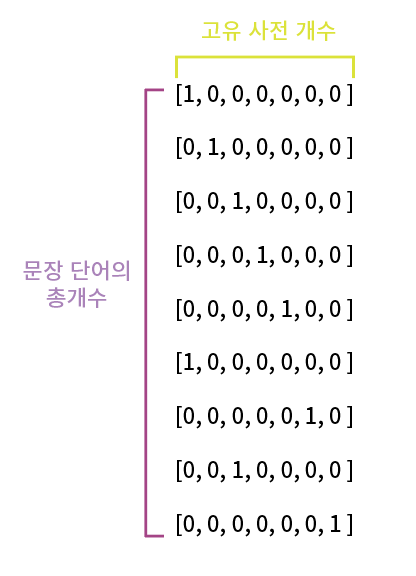
행의 개수 : 문장 내 단어의 총 개수
열의 개수 : 중복 제외한 고유 사전의 개수
shape를 찍어보면
(10,7)이 나온다.
(단어 수, 사전개수)이다.
만약
'I am a boy and I am not a girl' 라는 문장이 N개가 있다면
(N, 단어 수, 사전개수) 즉, (N, 10, 7)로 shape가 찍힌다.
[1, 0, 0, 0, 0, 0, 0 ]
[0, 1, 0, 0, 0, 0, 0 ]
[0, 0, 1, 0, 0, 0, 0 ]
[0, 0, 0, 1, 0, 0, 0 ]
[0, 0, 0, 0, 1, 0, 0 ]
[1, 0, 0, 0, 0, 0, 0 ]
[0, 0, 0, 0, 0, 1, 0 ]
[0, 0, 1, 0, 0, 0, 0 ]
[0, 0, 0, 0, 0, 0, 1 ]
one-hot encording을 하면 대부분의 값들이 0으로
채워진 것을 볼 수 있는데,
이 상태로 모델에 넣으면 학습이 안된다.
대부분의 숫자가 0이여서 학습을 하면 0으로 수렴해버린다.
이를 차원의 저주라고 한다.
Embedding Layer
이 때 해결을 할 수 있는 법이 Embedding Layer를 사용하는 방법이다.
큰 차원을 그대로 넣어주는 것이 아니라
차원을 줄여준 후 학습을 시킨다.
120개의 단어, 1000개의 고유사전이 있다고하자.
shape = (120, 1000)
[1, 0, 0, 0, 0, 0, 0 ...., 0]
[0, 1, 0, 0, 0, 0, 0 ...., 0]
[0, 0, 1, 0, 0, 0, 0 ...., 0]
.
.
.
[0, 0, 0, 0, 0, 0, 0 ...., 1]
1000개의 차원을 16차원으로 Embedding Layer를 사용해서 축소를 시키면
shape = (120, 16)
[0.23, 1.13, -0.12, ...1.59, 0.11]
[1,01, 0.41, -0.89, ...0.98, 0.19]
.
.
.
[0.56, -0.09, -0.01, ... 0.98, 0.19]
안에있던 값들이 0이 아닌 실수, 즉 백터값으로 변환이 되는 것을 볼 수 있다.
Embedding Layer를 사용하는 또 하나의 이유가 있다.
I am a boy and I am not a girl
앞서 one-hot encording을 시켜서 단어들의 관계성을 없앤다고 했는데
단어들의 관계성을 아예 없어버리면
딥러닝이 사람처럼 boy와 girl이 비슷한 느낌의 단어라는 것을 알 수 없다.
하지만
벡터화를 시키면,
그래프 상에서 유사한 단어들끼리 그룹화가 되는 것을 알 수 있고
반대어의 경우에는 멀리 떨어져 있는 것을 볼 수 있다.
정리하자면
Embedding Layer를 사용하는 이유
1. 차원의 저주
2. 벡터화를 이용한 단어간의 관계 파악
code
shape = (120, 1000)을 shape = (120, 16)로 변환
Embedding(vocab_size, embedding_dim, input_length = max_length)
vocab_size에는 인풋차원(1000)을 넣어준다.
embedding_dim 에는 아웃풋 차원(16)을 넣어준다.
input_length에는 문장의 길이(120)을 넣어준다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [딥러닝] LSTM(Long Short Term Memory) (8) | 2022.02.25 |
|---|---|
| [딥러닝] RNN (Recurrent Neural Network) - 순환신경망 구조 (12) | 2022.02.24 |
| [딥러닝] Windowed Dataset 구성 옵션 ( Tensorflow 시계열 데이터 분석) / 딥러닝 미래 예측하기 (2) | 2022.02.22 |
| [딥러닝] Activation Function 활성함수 한번에 이해하기(Sigmoid, Softmax, Relu) (6) | 2022.02.18 |
| [딥러닝] Convolution Neural Network (CNN) 합성곱 신경망 - 간단하고 쉽게 이해하기 (12) | 2022.02.17 |




댓글