Convolution Neural Network (CNN) 합성곱 신경망
CNN
Dense 레이어 = 연산을 담당하는 레이어이고.
CNN = 들어오는 데이터(features)에 대한 특성을 추출하는 레이어이다.
따라서 모델링을 할 때에
특성 추출을 먼저한 후 연산을 해야하니
윗부분이 특성을 추출하는 레이어가 자리잡고
아랫부분이 연산을 담당하는 레이어가 자리잡는다.
input 레이어는 하나의 이미지에 대해서 굴곡 등..특성을 추출하고
그 추출한 이미지를 모아둔 것을 feature maps라고 한다.
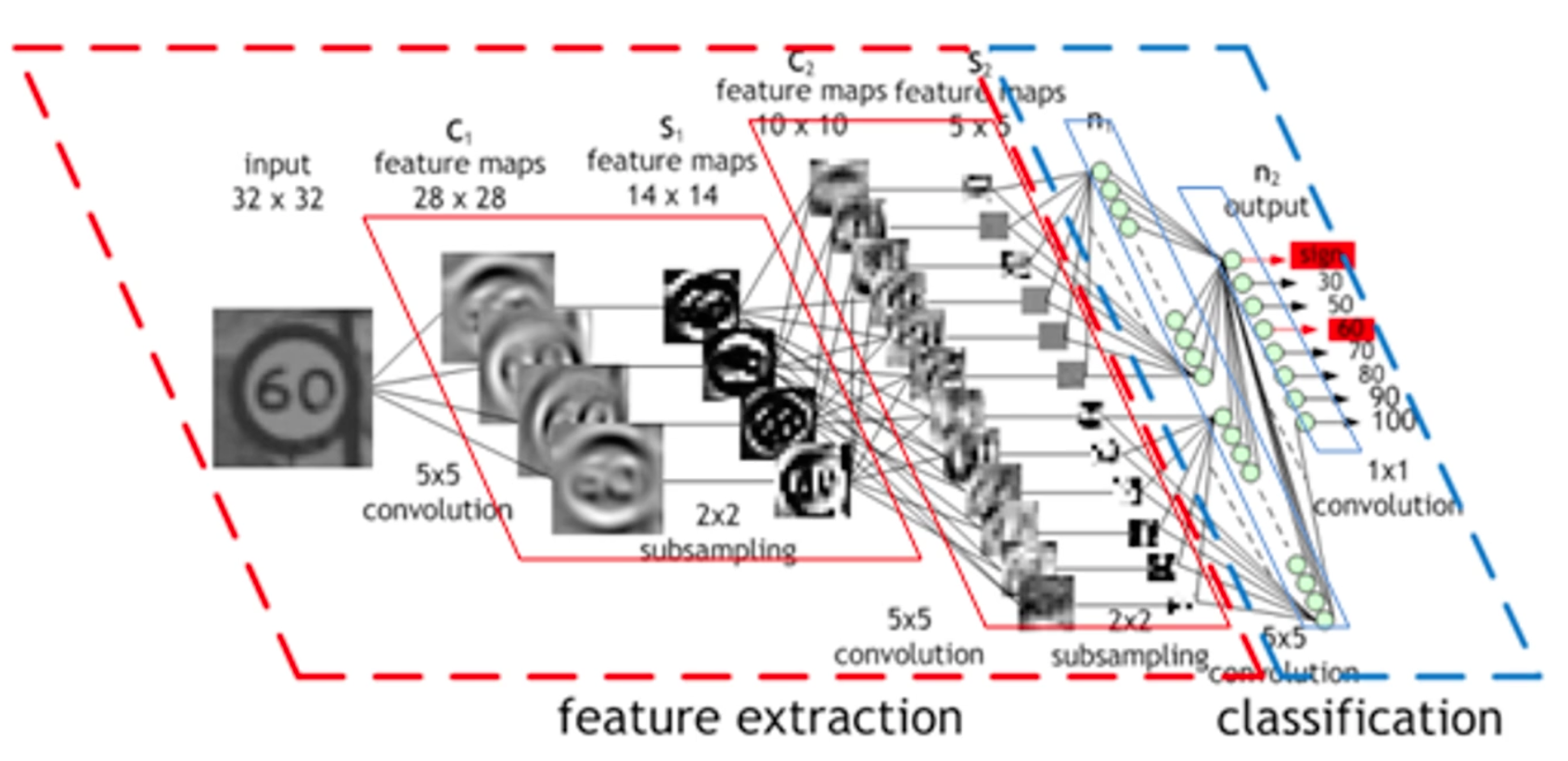
계속 cnn층을 깊게쌓으면서 특성 추출을 해가는 것이 위 그림에 대한 설명이다.
여기까지가 CNN의 기본 개념 끝!
Dense VS CNN
예를들어 고양이 사진을 가지고
이 사진이 고양인지 아닌지를 알 수 있는 모델을 만든다고 하자.
만약에
Dense layer만 사용해서 모델링을 구현한다 해보자
Dense layer는 모든 레이어들이 연결되어있다.

따라서 고양이 얼굴이 아닌 배경에 대한 layer들까지도 연산이 된다.
불필요한 연산들을 많이 한다는 뜻이다.
하.지.만
CNN은 Localization추출을 해서
정확히 고양이의 얼굴이 있는 부분을 추출할 수 있다.
필요없는 배경이 아닌 눈, 코, 입, 귀 등을 먼저 추출해서
이 추출한 feature로 연산을 한다.
그럼 Dense보다 계산량을 많이 줄일 수 있고
효율적인 학습을 할 수 있다.
CNN은 어떤 방식으로 동작을 하는가?
예를 들어보자
사진기를 들고 갔는데 찰칵해가지고 풍경 사진을 찍었다고 하자.
원래 풍경이 있는데 사진기의 렌즈를 통해서 사진을 만들어냈다
풍경 = 원본
렌즈 = CNN의 필터
사진 = feature map

위 이미지를 토대로 합성곱 연산을 할 것이다.
원본이미지와 필터를 첫번째 칸에 나란히 겹쳐서 곱을한다.
| 3 * 12.0 | 3 * 12.0 | 2 * 17.0 |
| 0 * 10.0 | 0 * 17.0 | 1 * 19.0 |
| 3 * 9.0 | 1 * 6.0 | 1 * 12.0 |
위 계산의 답을 모두 더한
숫자를 feautre map의 가장 첫 부분에 적는다.
다음으로는
필터를 한 칸 옆으로 이동해서 원본에 겹쳐준다.
또 다 곱하고 더해서 feature map의 두번째 칸에 답을 적어
feature map을 채우는 방식이다.
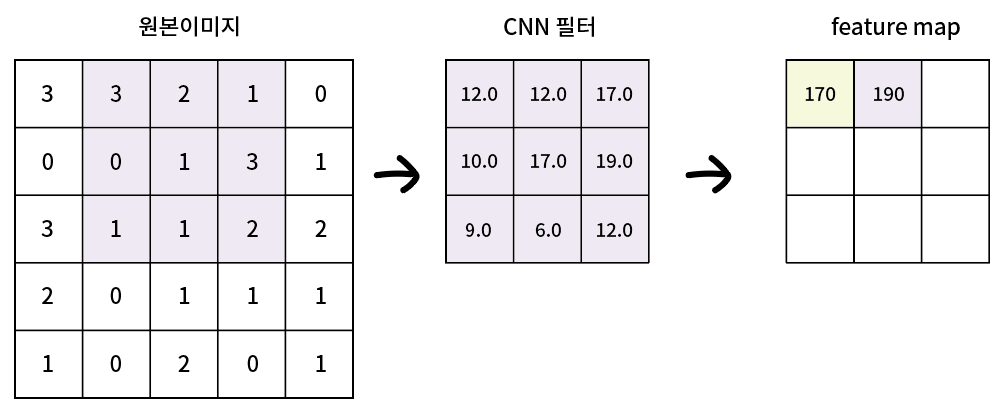
여기서 알 수 있듯이
원본사이즈 5x5
CNN 필터 사이즈 3x3
Feature map 상이즈 3x3이다.
원본사이즈보다 feature map이 줄은 것을 알 수 있다.
원본사이즈가 줄어드는 것이 싫다면
제로 패딩을 덧대주면 사이즈가 변하는 것을 막을 수 있다.
이것은 본인 맘.

아무튼
기본적으로
3*3필터를 사용했을 때 가로세로 2px씩 줄어드는 결과가 나오게된다.
150*150 이미지를 사용하면 148*148의 결과가 나온다.
필터 안 랜덤 갯수들의 값은 30장이면 30장 모두 랜덤하게 다르다.
때문에
필터의 갯수만큼 다양한 특성들이 추출된다.
모델링 코드
Conv2D(64,(3,3), activation = 'relu'),-> Conv2D인 이유는 이미지가 2D이기 때문
-> 64장의 필터갯수가 추출.
->필터의 사이즈는 3*3
정리
1. CNN은 Localization(지역 특성)을 하는 것이 특징이다.
2. feature들을 먼저 추출하고 추출한 feautre로 연산을 한다.
3. Dense보다 계산을 줄일 수 있고 효율적으로 학습을 할 수 있다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [딥러닝] Windowed Dataset 구성 옵션 ( Tensorflow 시계열 데이터 분석) / 딥러닝 미래 예측하기 (2) | 2022.02.22 |
|---|---|
| [딥러닝] Activation Function 활성함수 한번에 이해하기(Sigmoid, Softmax, Relu) (6) | 2022.02.18 |
| [논문리뷰] VGG Net - Very Deep Convolutional Networks for large-scale image recognit (4) | 2022.02.16 |
| [딥러닝] Dense Layer (Fully Connected Layer) 이해하기 (0) | 2022.02.09 |
| [딥러닝] classification neural network(분류신경망) (0) | 2022.01.24 |




댓글