CCTV 이상행동 판별 시스템 제작 - 04. 다시시작! 데이터셋 사진찍기(feat.labelImg)
사진을 찍자!
결국..힘들게 정제한 데이터셋을 버리고 특징을 확실히 잡을 수 있는 데이터셋을 직접 만들기로 했다.
그리고 기존에 7개였던 카테고리 중 비슷하게 인식 될만한 것들을 다 버리고 (폭행, 실신, 기물파손, 계단전도, 개집표기 무단진입) 5개로 줄였다. 일단 특징이 되는 것들을 학습시키고 점점 데이터셋을 늘려가면서 조정하는 방법을 선택!
정말 데이터셋을 직접 만들지는 상상도 못했다ㅋㅋㅋ




파트너, 옷, 장소를 바꿔가면서 상황별로 40장씩 촬영을 했다.
사진의 양은 적지만 yolov5 자체가 Augmentation을 해주는 점을 이용해서 처음엔 적은 용량으로 시작했다.
🚫 촬영 시 주의한 점! 🚫
1. 사진의 크기와 labeling할 바운딩 박스의 크기를 비슷하게 맞춰가며 촬영.
2. CCTV처럼 살짝 위에서 촬영
3. 다양한 구도와 장소에서 촬영



기물파손은 기물의 종류를 의자와 소화기로 국한시켜 모델이 명확한 특징을 잡을 수 있도록했다.
폭행 데이터의 경우에는 무언가를 때리는 모습이 기물파손과 겹칠 수 있어 발을 사용하지 않았다.



개집표기 무단진입은 직접 촬영할 수 없어서 기존에 가지고 있는 데이터 중
개집표기를 높게 뛰어넘는 사진이나, 개찰구가 닫히는 사진 등 특징이 명확한 것들을 추출했다.
Labeling - labelImg 사용하기
이미지를 구했으니 해야할 것은?
이제 정답데이터를 만들어 줘야한다.
수업 때 사용한 라벨링 프로그램은 Labelme 라는 프로그램이다.
사진에 바운딩 박스를 만들어주면 x,y,w,h가 들어있는 json파일 형태로 만들어 준다.
Labelme를 이용하면 json파일을 YOLO형식의 txt파일로 전처리를 해줘야한다.
하지만 귀찮은 일이니..
cat, cx, cy , w, h의 txt파일로 만들어주는 LabelImg라는 프로그램을 찾았다.
>>> pip3 install labelImg
>>> labelImg
설치를 하고, labelImg를 입력하면 프로그램이 뜬다.
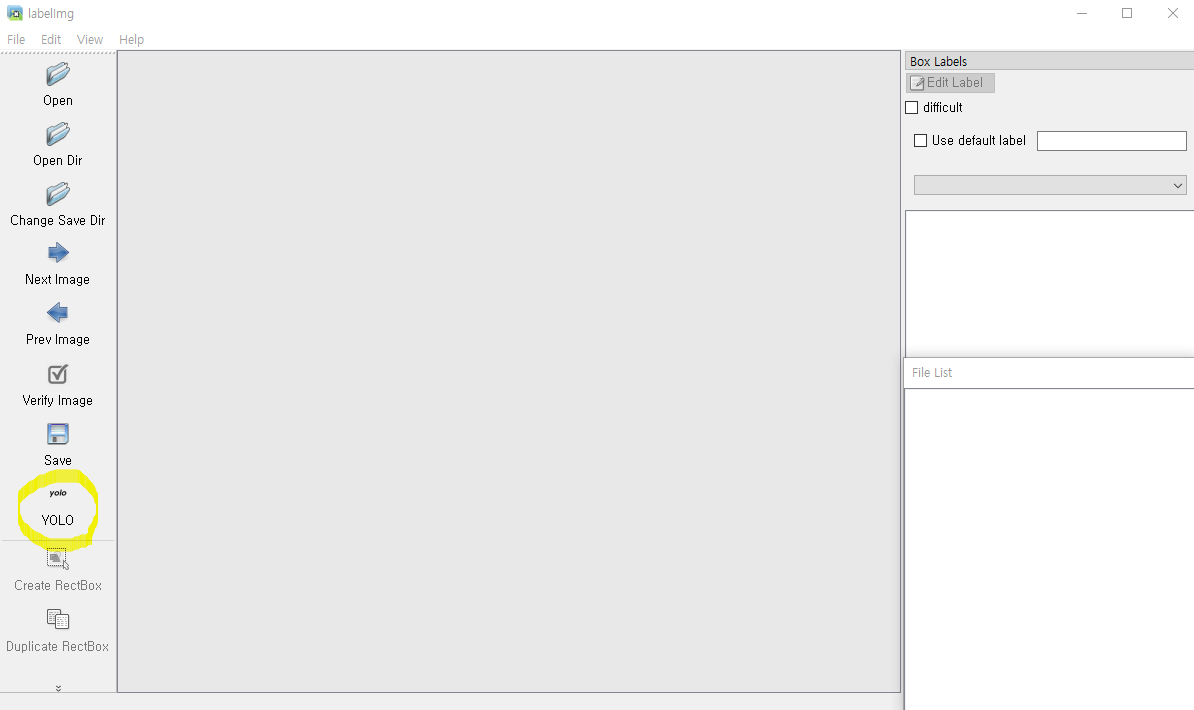
YOLO버튼을 클릭하면 바운딩박스 된 좌표가 cat,cx,cy,w,h 형태로 바뀌어 저장이 된다.
Change Svae Dir을 눌러서 labeling된 파일을 저장할 디렉토리를 선택한다.
Open Dir로 이미지를 불러와 바운딩 박스를 그려줄 수 있다.

우측 하단의 File List에서 원하는 img를 고르후 단축키(W)를 누르면 사각형을 그릴 수 있다.
대각선 스크롤로 사각형을 그리면 label 이름을 입력할 수 있는 창이 뜬다.
ok를 누르면 저장 경로에 img와 같은 이름의 txt파일이 만들어진 것을 볼 수 있다.
많은 사진을 labeling하는 것도 노가다이지만 대충하면 안된다.(최대한 빈공간이 없이!)
컴퓨터에게 정답을 알려주는 데이터이기 때문에 팀원 모두 같은 기준을 가지고 바운딩박스를 그려줘야한다.
예를들어 위 사진의 경우 개집표기를 특징으로 잡기 위해, 사람 뿐 아니라 개집표기까지 함께 라벨링을 해주었다.


기존의 폭행 데이터는 한 명씩 라벨링이 되어있었다면 이번엔 두 사람을 한 번에 표기를 해주었고
기물 파손 데이터도 기물까지 한번에 라벨링 해주었다.
학습 2트 및 문제점 발견.
이렇게 만든 데이터 약 300여개로 재학습을 시켜주었다.

mAP가 확 높아진 것을 알 수있다.
특히나 '폭행'과 '개집표기 무단침입'의 mAP는 90이 넘는 것을 볼 수 있엇다.
하지만 '실신','계단전도'는 비교적 낮은 mAP를 보였다.
'실신'과 '계단 전도'의 특징이 비슷하여 구분을 하지 못한 것으로 보였다.
특히나 웹캠을 이용하여 test를 해보았을 때,
오버피팅(폭행, 개집표기 무단침입)과 언더피팅(실신, 계단전도)이 동시에 일어나는 현상을 볼 수 있었다
여기서 발견한 문제점들이 있었다.
1. YOLOv5 자체의 Aumgentaion(지난번 학습에서도 영향을 미친 부분인 것같다.)
yolov5 모델은 적은 학습데이터를 디폴드로 Augmentation을 시켜주어 데이터의 양을 늘린 후 학습시켜준다.

위 학습 결과의 정보는 exp3 폴더에 들어있다. (model summary 가장 아래에 exp3라고 적혀있다)
weights 폴더에는 학습결과의 best(가장좋은), last(마지막) 가중치들이 저장되어있다.
이 pt파일을 가지고 여러 어플리케이션에 적용이 가능하다.
train_batch 파일을 보면 어떻게 Augmentation이 되어서 학습이 되었는지 볼 수 있다.


자세히 보면,




카테고리의 특징이 아닌 형태가 crop되어 라벨링이 되어있는 것을 볼 수 있었다.
발만 잘라 놓고 계단 전도라고 하던가,
사람이 한 명만 보이는 사진이거나 두 사람의 다리만 crop되어있는 사질을 폭행이라고 라벨링이 되어있었다.
심지어 형태를 구분할 수 없는 사진까지 라벨링이 되어있었으니
당연히 학습 결과가 이상할 수 밖에..

다음 경로로 들어가면 옵션값을 수정할 수 있다.
high, low, med의 차이점은 Augmentation의 강도의 정도라고 들었다.(아마..)
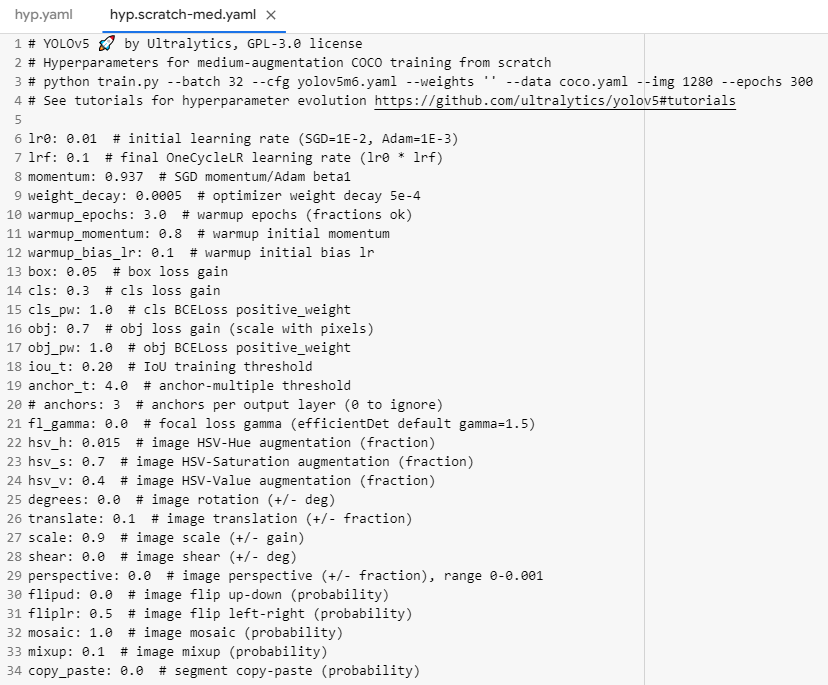
여기서 뺄 거 뺴고, 조정해줄 부분을 조정할 수 있다.
구글링하면 어떤 뜻인지 조정 범위는 무엇인지 다 알려준다.
우선적으로 뺴야할 것은 위에서 말했듯이 crop을 하는 mosaic(여러장의 사진을 잘라서 한장으로 만들어준다)의 값을 조정.
누워있는 사람과 서있는 사람을 구별하기 위해서 이미지를 rotation이나 reflect하는 부분도 조정해주었다.
2. 데이터셋의 양이 적다는 것.
처음에는 사진을 직접 찍어서 데이터 셋을 만든다는 것이 불안했기에 적은양으로 학습을 시작했다.
따라서 데이터 셋의 양의 부족하기도 했고, feature가 명확하지 않았을 것이다.
테스트 해보면서 다양한 특징의 데이터들을 조금씩 늘려가며 학습시킬 예정이다.
'Project' 카테고리의 다른 글
| CCTV 이상행동 판별 시스템 제작 - 05. 사진찍기 -> 라벨링 -> 모델 학습의 무한 굴레 (1) | 2022.08.19 |
|---|---|
| CCTV 이상행동 판별 시스템 제작 - 03. YOLOv5 모델 훈련시키기 (1) | 2022.08.17 |
| CCTV 이상행동 판별 시스템 제작 - 02. 데이터셋 확보 및 정제 / YOLOv5 labels.txt 만들기 (2) | 2022.08.16 |
| CCTV 이상행동 판별 시스템 제작 - 01. 주제선정 및 기획 (2) | 2022.08.14 |




댓글